# (十一) 学习正则表达式的简单方法
正则表达式是繁琐的,但它是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感。
# 一、什么是正则?
- 正则表达式是一种被用于从文本中检索符合某些特定模式的文本。
- 正则表达式可以被用来替换字符串中的文本、验证表单、基于模式匹配从一个字符串中提取字符串等等。
先来看看一个经典场景:
想象一下,您希望在用户填写用户名时遵守以下规则,仅包含字母,数字,下划线和连字符。同时我们还想限制用户名中的字符数量。这时我们可以使用以下正则表达式来验证用户名:
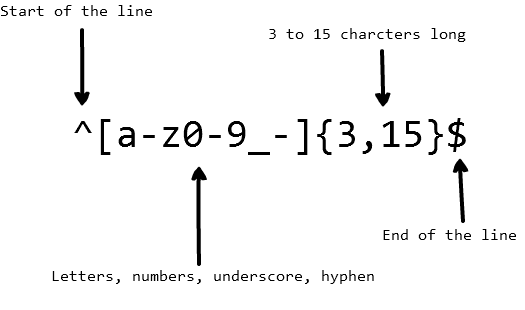
下面的代码就是上面正则表达式的简单应用
<body>
<input type="text" id="input" />
<button onclick="test()">验证</button>
<script>
const oInput = document.getElementById("input");
const reg = /^[0-9a-z_-]{3,15}$/;
function test() {
const e = oInput.value;
if (e.match(reg)) {
window.alert("用户名验证通过");
} else {
window.alert("⚠️验证错误⚠️");
}
}
</script>
</body>
上面的规则组合是我们根据目标字符串的特点分析出来的,接下来我们来看看它的基本语法吧
# 1.1 test() 检测字符串
test() 方法用于检测一个字符串是否匹配某个模式。
RegExpObject.test(string)
返回值:
如果字符串string中含有与RegExpObject匹配的文本,则返回true,否则返回false。
示例:
/abc/.test('123'); // false
/abc/.test('abcd'); // true
# 1.2 replace() 替换字符串
replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。
返回值:
一个新的字符串,是用 replacement 替换了 regexp 的第一次匹配或所有匹配之后得到的。
示例:
'yuguang up'.replace(/yuguang/, '余光'); // "余光 up"
# 二、元字符
元字符是正则表达式的基本组成元素。元字符在这里跟它通常表达的意思不一样,而是以某种特殊的含义去解释。
常用的元字符如下:
| 元字符 | 描述 | 举例 |
|---|---|---|
. | 匹配除换行符以外的任意字符 | /.ing/.test('eating') |
[xyz] | 字符集,匹配方括号中包含的任意字符 | '[abc]' 可以匹配 "plain" 中的 'a' |
[^xyz] | 负值字符集合。匹配未包含的任意字符 | 负值字符集合。匹配未包含的任意字符。例如, |
* | 匹配前面的子表达式零次或多次 | /abc*/.test('ab') 匹配 0 次是可以的 |
+ | 匹配前面的子表达式零次或多次 | /abc*/.test('abcc') |
? | 匹配前面的子表达式零次或一次 | /123?/.test('12') |
{n,m} | 花括号,匹配前面字符至少 n 次,但是不超过 m 次 | |
(xyz) | 字符组,按照确切的顺序匹配字符 xyz | |
| | 分支结构,匹配符号之前的字符或后面的字符 | |
\ | 转义符,它可以还原元字符原来的含义,允许你匹配保留字符 | |
^ | 匹配行的开始 | |
$ | 匹配行的结束 |
# 2.1 英文句号
英文句号,在匹配时也与它实际意义不同,它是元字符中最简单例子.
我们要匹配 "End" 这个字符串,还要仅仅运用 ".",可以怎么做?
const reg = /.nd/
reg.test('End'); // true
# 2.2 字符集 和 否定字符集
字符集又叫字符类,通常情况下它表示,匹配大括号内所包含的任意一个字符
我们要匹配 "End"或"end" 时,可以怎么做?
const reg = /[Ee]nd/
reg.test('End'); // true
reg.test('end'); // true
reg.test('and'); // false
**注意1:**元字符^代表从字符串的起始位置开始匹配,但在字符集内,它表示否定或取反
// 注意1:
const reg = /[^Ee]nd/
reg.test('End'); // false
reg.test('end'); // false
reg.test('and'); // true
**注意2:**元字符.代表换行符以外的任意字符,但在字符集内,它就代表英文句号
// 注意2:
const reg = /ok[.]/
reg.test('is ok!'); // false
reg.test('is ok.'); // true
# 2.3 重复
重复通常是匹配某一个规则多次,这和花括号的部分作用重合,区别在于匹配的次数问题
# 2.3.1 星号
星号(*)表示匹配上一个匹配规则零次或多次。
const reg = /yuguang*/
reg.test('yuguan'); // true
reg.test('yuguanggggg'); // true
# 2.3.2 加号
加号(+)表示匹配上一个匹配规则1次或多次。
const reg = /yuguang+/
reg.test('yuguang'); // true
reg.test('yuguan'); // false
# 2.3.3 问号
问号(?)用来表示前一个字符是可选的。该符号匹配前一个字符零次或一次。
表示:可选的字母y紧跟小写字母uguang
const reg = /y?uguang/
reg.test('uguang'); // true
reg.test('yuguang'); // true
# 注意
*如果出现在字符集之后,它表示整个字符集的重复。
const reg = /[0-9]*/
reg.test('12345'); //true
# 2.4 花括号
在正则表达式中花括号用于指定字符或一组字符可以重复的次数。例如正则表达式 [0-9]{2,3},表示:匹配至少2位数字但不超过3位
- 我们可以省略第二个数字:则正则表达式
[0-9]{2,},表示:匹配 2 个或更多个数字。 - 我们也可以删除逗号:则正则表达式
[0-9]{2},表示:匹配正好为 2 位数的数字。
const reg = /[0-9]{1,}/
reg.test(''); //false
reg.test('1'); true
# 2.5 字符组
字符组是一组写在圆括号内的子模式 (...),(xyz)按照确切的顺序匹配字符x->y->z
let str = 'ababcdcd';
str.replace(/ab/, '替换'); // "替换abcdcd"
str.replace(/(ab)*/, '替换'); // "替换cdcd"
注意:
正如我们看到的,把量词放在一个字符组之后,它会重复整个字符组。 例如正则表达式 (ab)* 表示匹配零个或多个的字符串“ab”。
# 2.6 分支(或)
在正则表达式中垂直条 | 用来定义分支结构,分支结构就像多个表达式之间的条件。现在你可能认为这个字符集和分支结构的工作方式一样。 但是字符集和分支结构巨大的区别是字符集只在字符级别上有作用,然而分支结构在表达式级别上依然可以使用。 例如正则表达式 (T|t)he|car,表示:匹配大写字母 T 或小写字母 t,后面跟小写字母 h,后跟小写字母 e,或匹配小写字母 c,后跟小写字母 a,后跟小写字母 r。
const reg = /(T|t)he|car/
reg.test('The'); // true
reg.test('tcar'); // true
# 2.7 转义特殊字符
正则表达式中使用反斜杠 \ 来转义下一个字符。这将允许你使用保留字符来作为匹配字符:
{ } [ ] / \ + * . $ ^ | ?
let reg = /\.{1}/
'aa.bb.cc'.replace(reg, '-'); // "aa-bb.cc"
# 2.8 定位符
在正则表达式中,为了检查匹配符号是否是起始符号或结尾符号,我们使用定位符。
# 2.8.1 插入符号
插入符号 ^ 符号用于检查匹配字符是否是输入字符串的第一个字符。
// 因为起始不是a->b->c 替换失败
let reg = /^abc/
'not abc'.replace(reg, '***'); // "not abc"
# 2.8.2 $符号
美元 $ 符号用于检查匹配字符是否是输入字符串的最后一个字符。
// 因为起始不是a->b->c 替换失败
let reg = /abc$/
'not abc'.replace(reg, '***'); // "not ***"
# 三、简写字符集
正则表达式为常用的字符集和常用的正则表达式提供了简写。简写字符集如下:
| 简写 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配所有字母和数字的字符:[a-zA-Z0-9_] |
| \W | 匹配非字母和数字的字符:[^\w] |
| \d | 匹配数字:[0-9] |
| \D | 匹配非数字:[^\d] |
| \s | 匹配空格符:[\t\n\f\r\p{Z}] |
| \S | 匹配非空格符:[^\s] |
注意:这里并不是全部的简写,仅列出了常用或常见的。
我们依次为表格中的简写配一个示例
匹配除换行符以外的任意字符:
// 将换行符前的内容打码
'hi yuguang \n hi xiaoming'.replace(/.+/, '***'); // "***\n hi xiaoming"
匹配所有字母和数字的字符:
'123'.replace(/\w/, '***'); // ***
匹配数字:
// 匹配存在连续3位数字的字符串
/\d{3}/.test('1a2b3c444'); // true
匹配空格符:
// 将空格替换成 :
'12 59'.replace(/\s/, ':'); // "12:59"
# 四、断言
编写代码时,我们总是会做出一些假设,断言就是用于在代码中捕捉这些假设,而正则中的断言也是类似的存在:
先来看看都有哪些断言
| 符号 | 描述 |
|---|---|
| ?= | 正向先行断言 |
| ?! | 负向先行断言 |
| ?<= | 正向后行断言 |
| ?<! | 负向后行断言 |
# 4.1 正向先行断言
正向先行断言认为第一部分的表达式的后面必须是先行断言表达式。返回的匹配结果仅包含与第一部分表达式匹配的文本。
let reg = /[Tt]he(?=\syuguang)/
reg.test('the yuguang'); // true
reg.test('the xiaoming'); // false
表示:匹配T或t,->h->e。 在括号中,我们定义了正向先行断言,它会引导正则表达式引擎匹配后面跟着 yuguang 的 The 或 the。
# 4.2 负向先行断言
当我们需要指定第一部分表达式的后面不跟随某一内容时,使用负向先行断言。
let reg = /[Tt]he(?!\syuguang)/
reg.test('the xiaoming'); // true
# 4.3 正向后行断言
不难理解,后行就是匹配规则在之后的,用于获取跟随在特定模式之后的所有匹配内容。
例如正则表达式 (?<=(T|t)he\s)(fat|mat),表示:从输入字符串中获取在单词 The 或 the 之后的所有 fat 和 mat 单词。
let reg = /(?<=(T|t)he\s)(fat|mat)/
'The fat cat'.replace(reg, '***'); // "The *** cat"
# 4.4 负向后行断言
获取跟随在特定模式以外的所有匹配内容
let reg = /(?<=(T|t)he\s)(fat|mat)/
reg.test('the fat cat'); // false
// 任意个的数字 + . | 数字 + 任意个数字
/(\d+(\d|\.)\d+)(\w)/
# 五、修饰符
不知道大家对上面的例子是否存在疑问,比如
- 匹配一段规则,可以做到全局替换吗?
- 如果换行了怎么办?
- ...
这就又引出了修饰符:因为它会修改正则表达式的输出。这些标志可以以任意顺序或组合使用,并且是正则表达式的一部分。
| 标记 | 描述 |
|---|---|
| i 不区分大小写:将匹配设置为不区分大小写。 | |
| g | 全局搜索:搜索整个输入字符串中的所有匹配。 |
| m | 多行匹配:会匹配输入字符串每一行。 |
# 5.1 不区分大小写
i 修饰符用于执行不区分大小写匹配。
'Hello'.replace(/H/i, '*'); // "*ello"
# 5.2 全局搜索
g 修饰符用于执行全局匹配(会查找所有匹配,不会在查找到第一个匹配时就停止)
'112233-112233-112233'.replace(/(112233)/g, '密码'); // "密码-密码-密码"
# 5.3 多行匹配
m 修饰符被用来执行多行的匹配。正如我们前面讨论过的 (^, $),使用定位符来检查匹配字符是输入字符串开始或者结束。但是我们希望每一行都使用定位符,所以我们就使用 m 修饰符。
'The fat\n cat sat\n on the mat'.replace(/.(at)$/gm, '结尾');
// "The 结尾\n cat 结尾\n on the 结尾"
# 六、常见正则练习
# 6.1 电话号码匹配
像电话号码的匹配规则其实没有绝对正确的答案,先来分析一下下面正则要匹配的手机号应该符合什么样的规则?
正则:
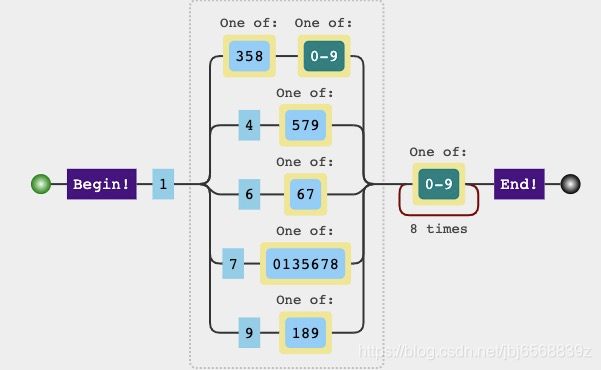
`/^1([358][0-9]|4[579]|6[67]|7[0135678]|9[189])[0-9]{8}$/`
分析:
- 第一位一定是
1 - 第二位+第三位:要根据括号内的分支结构区分。分别是:
- 第二位:3、5、8 => 第三位:任意数字;
- 第二位:4 => 第三位:5、7、9;
- 第二位:6 => 第三位:6、7;
- 第二位:7 => 第三位:0、1、3、5、6、7、8;
- 第二位:9 => 第三位:1、8、9;
- 剩余八位:任意8位数组排列组合`
手机号正则表达式虽然很长,但实际分析起来并不复杂,在知道确切的规则后相信大家都能慢慢推导出来,话不多说直接上图:
图示:
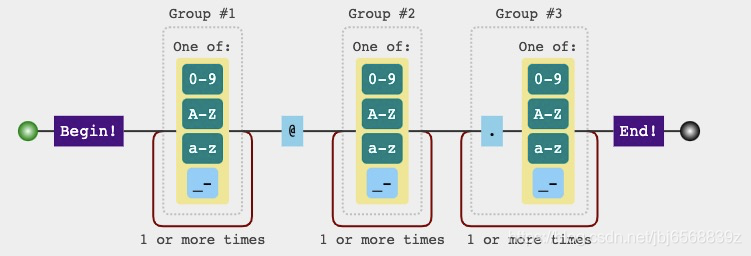
# 6.2 邮箱校验
正则:
/^([a-zA-Z0-9_\-]+)@([a-zA-Z0-9_\-]+)(\.[a-zA-Z0-9_\-]+)$/
分析:
- 起始:任意大小写字母或下划线或或数字 + @
- 中间:任意大小写字母或下划线或或数字 + .
- 结束:任意大小写字母或下划线或或数字
图示:
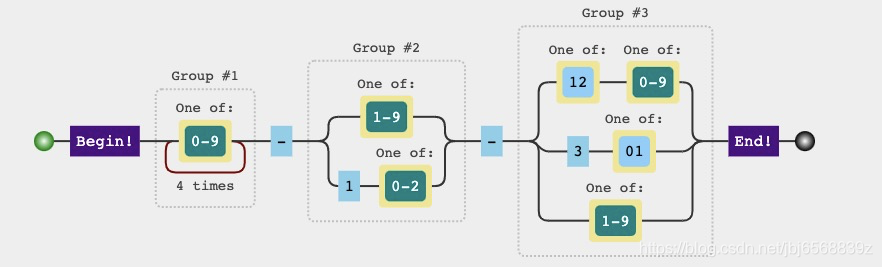
# 6.3 xxxx-xx-xx日期转换
有这样一个需求,明确的知道时间格式是:“2021-1-1”和“2021-12-1”,要准确的提取出年、月、日需要怎么做的?(只考虑正则哦)
这次我们先分析后写正则:
分析
- 年:固定四位数字:
^[0-9]{4} - 月:1-2位数字:
- 1位时:
[1-9] - 2位时:
1[0-2]
- 日:1-2位数字:
- 1位时:
[1-9] - 2位时:
[12][0-9]|3[01]$
正则
// $1 $2 $3
const reg = /^([0-9]{4})-([1-9]|1[0-2])-([12][0-9]|3[01]|[1-9])$/
// 测试代码
const [,year, month, day] = '2012-1-12'.match(reg)
图示:
# 写在最后
- 花名:余光
- WX:j565017805
- 邮箱:webbj97@163.com
# 其他沉淀
